Loading... ## 线性表 ### 线性表的定义 线性表 (Linear LIst) 时具有**相同数据类型**的 $n (n \geq 0)$ 个数据元素的**有限序列**,其中 $n$ 为**表长**。当 $n = 0$ 的时候线性表是一个**空表**。线性表 $L$ 一般表示为: $$ L = (a_1, a_2, ... , a_i, a_{i + 1}, ... , a_n) $$ - $a_i$ 表示线性表中的第 $i$ 个元素,这个 $i$ 是线性表的**位序**。(注意位序是**从 1 开始**的,而数组的下标一般是从 0 开始的) - $a_1$ 是**表头元素**, $a_n$ 是**表尾元素**。 - 除第一个元素外,每个元素有且仅有一个**直接前驱**;除最后一个元素外,每个元素有且仅有一个**直接后继**。 > 线性表是一种逻辑结构,表示元素之间一对一的相邻关系。顺序表和链表是指存储结构,两者属于不同层面的概念。 ### 线性表的基本操作 - `InitList(&L)` :初始化。创造一个空的线性表 $L$ , **分配内存空间**。 - `DestroyList(&L)` :销毁。销毁线性表,并**释放**占用的内存空间。 - `ListInsert(&L, i, e)` :插入。在表 $L$ 中第 $i$ 个位置上插入元素 $e$ 。 - `ListDelete(&L, i, &e)` : 删除。删除表 $L$ 中第 $i$ 个位置的元素,并用 $e$ 返回被删除的元素。 - `LocateElem(L, e)` :按值查找。在表 $L$ 中查找具有给定关键字 $e$ 的元素。 - `GetElem(L, i)` :按位查找。获取表 $L$ 中第 $i$ 个位置上的元素的值。 - `Length(L)` :获取表长。返回线性表 $L$ 的长度。 - `PrintList(L)` :输出线性表。 - `Empty(L)` :线性表判空。 > 基本操作的实现取决于采用哪种数据结构。 ## 顺序表 ### 顺序表的定义 用**顺序存储**的方式实现线性表。 - 顺序存储:把**逻辑上相邻**的元素存储在**物理位置上也相邻**的存储单元中,元素之间的关系由存储单元的邻接关系来体现。 ### 顺序表的实现 #### 静态分配 ```c++ typedef struct { ElemType data[INIT_SIZE]; int length; }SqList; // use this struct: SqList *p = (SqList *) malloc(sizeof(SqList)); ``` 静态分配定义的数组存放于栈中,变量释放会自动释放 `data` 占用的空间。 > typedef 关键字:数据类型重命名。不使用 typedef 的写法如下: > > ```c++ > struct SqList { > ElemType data[INIT_SIZE]; > int length; > }; > > // use this struct: > struct SqList *p = (struct SqList *) malloc(sizeof(struct SqList)); > ``` > > #### 动态分配 ```c++ typedef struct { ElemType *data; int MaxSize; int length; }SeqList; // use this code to allowcate memory for sequent list. L.data = (ElemType*)malloc(INIT_SIZE * sizeof(ElemType)); ``` `malloc` 分配的空间存放于堆中,需要手动用 `free` 函数来释放,不会自己释放。 ### 顺序表的特点 - **随机访问**。可以在 $O(1)$ 的时间内找到第 $i$ 个元素。 - 存储密度高。每个节点只存储数据元素。 - 拓展容量不方便。需要先分配一片更大的空间,再把原表中所有元素复制过去,最后释放原表。 - 插入删除复杂度高。插入删除都需要移动指定位置后面所有的元素。 ### 顺序表增删改查的实现 按照上面线性表的基本操作实现即可,懒得写了 (。・ω・。) ## 链表 ### 单链表 - 优点:不要求大片连续空间,改变容量方便。 - 缺点:不可随机存取,且需要消耗空间存放指针。 #### 实现 - 带头节点; - 不带头节点; #### 操作 - 建表; - 头插法; - 尾插法; - 插入; - 按位序插入; - 指定节点的后插 (前插) 操作; - 删除; - 按位序删除; - 指定节点的删除; - 查找; - 按位查找; - 按值查找; - 求表的长度; ### 双链表 相对单链表,多了一个指向前驱节点的指针,因此可以逆向检索。 边界情况需要特殊处理。 前向遍历和后向遍历的实现。 ### 循环链表 最后一个节点的指针指向头节点。 判空:头节点的下一个节点指向自己,表示这个循环链表是空链表。 循环单链表可以将指向头节点的指针 $L$ 修改为指向尾节点,这样可以在 $O(1)$ 的时间复杂度中对单链表的头尾进行操作。 ### 静态链表 > 用数组的方式实现的链表 单链表中的节点可以在内存中的任意地方,而静态链表则是分配了一整片空间来存放节点。 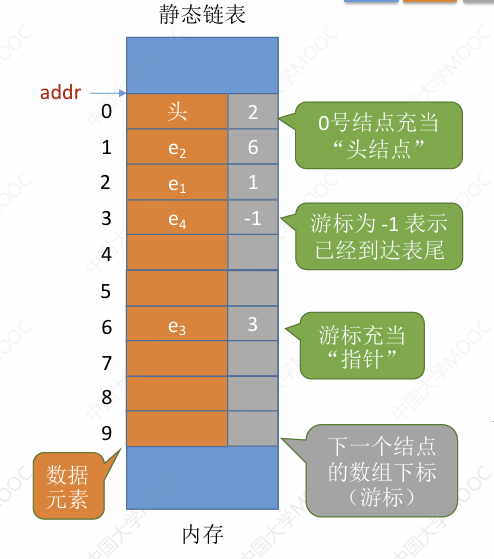 #### 代码实现 ```c++ typedef struct { ElemType data; int next; } SLinkList[MAX_SIZE]; ``` 另一种实现代码: ```c++ // another code implement: struct Node { ElemType data; int next; }; typedef struct Node SLinkList[MAX_SIZE]; ``` #### 优缺点 优点:增删操作不需要大量移动元素。 缺点:不能随机存取,只能从头节点开始一次往后查找。且容量固定不可变。 #### 场景 - 不支持指针的低级语言; - 数据元素数量固定不变的场景。(如操作系统的文件分配表 FAT) ## 问题模板 - **(...),实现线性表时,用顺序表好还是链表好?** 顺序表和链表的逻辑结构都是线性结构,都属于线性表。 但是二者的存储结构不同,顺序表采用顺序存储,[...] (顺序表的特点,带来的优点和缺点);链表采用链式存储,[...] (链表的特点,以及导致的优缺点)。 由于采用不同的存储方式实现,因此基本操作的实现效率也不同。当初始化时 [...] ;当插入一个数据元素时 [...] ;当删除一个数据元素时 [...] ;当查找一个数据元素时 [...] ; 最后修改:2024 年 04 月 28 日 © 允许规范转载 赞 如果觉得我的文章对你有用,请随意赞赏