Loading... ## 前言 这学期去当了个助教,OJ 又不支持直接导出学生的代码,所以只好自己动手把代码爬下来。因此接触了这个工具用来识别验证码。在这里记录一下 tesseract 的一些简单用法吧。 ## 准备 **我的环境:** Ubuntu 18.04 ### 安装 tesseract-ocr ```bash sudo apt install tesseract-ocr # 语言包酌情安装 ``` ### 安装 pytesseract ```bash pip install pytesseract ``` 这个库其实就是将 tesseract 的一些操作封装成 python 的类。其他平台安装参考[这里](https://github.com/tesseract-ocr/tesseract/wiki) > 最开始我尝试用 tesserocr ,但这个库死活安装不上去,反正我用 pytesseract 是达到了目的,就没管这个了。 ## 基本用法 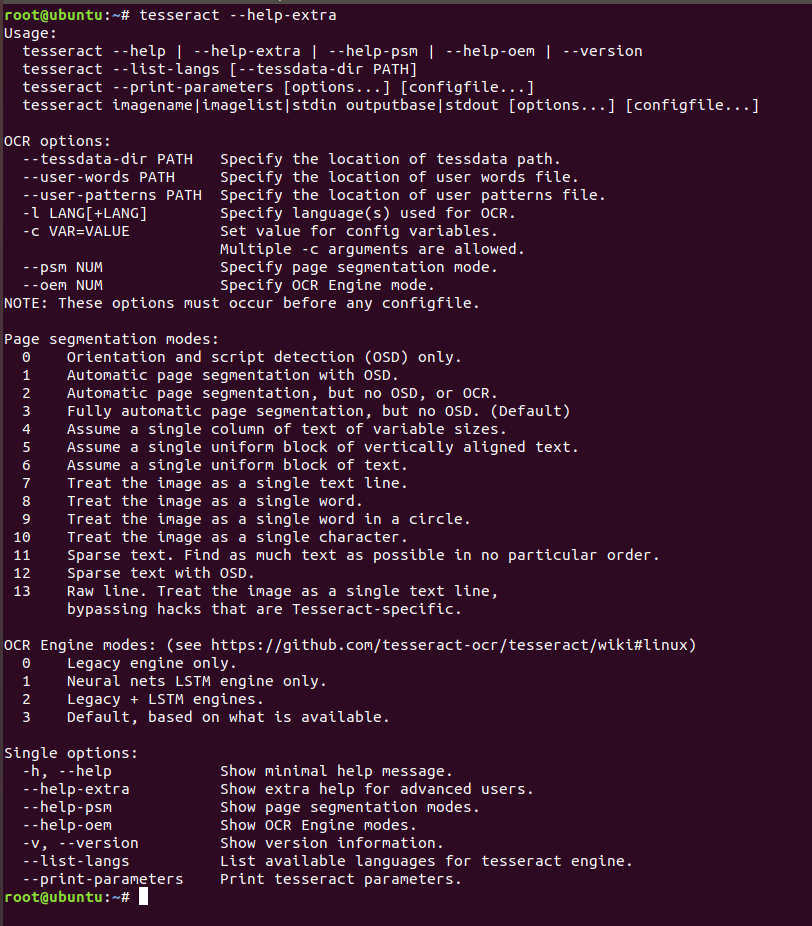 解释一下一些参数: - **imagename : ** 要转换的图片 - **outputbase : ** 保存结果的文件名 - **-l : ** 选择语言 - **-c :** 设定单项参数的值 - **--psm : ** 选择分页模式。几个模式翻译如下: - `0` =方向和脚本检测(OSD)。 - `1` =使用OSD自动分页。 - `2` =自动分页,但没有OSD或OCR - `3`=全自动页面分割,但没有OSD。(默认) - `4` =假设一列可变大小的文本。 - `5` =假定一个统一的垂直排列文本块。 - `6` =假设一个统一的文本块。 - `7` =将图像视为单个文本行。 - `8` =将图像视为一个单词。 - `9` =将图像视为一个圆圈中的单个单词。 - `10` =将图像视为单个字符。 单独的命令选项: | parameters | explain | | ------------------ | ------------------------ | | -h | 帮助信息 | | --help-psm | 显示分页模式 | | --help-oem | 显示引擎模式 | | -v | 版本信息 | | --list-langs | 查看当前可以使用的语言库 | | --print-parameters | 打印tesseract的控制参数 | ## 简单的例子  这是一张简单的图片,要识别这张图片可以使用以下语句: ```bash tesseract example_01.png stdout --psm=7 ``` 关于 tesseract 的训练后面再填坑吧,该写实验报告了…… > (随便写了个深大OJ的爬虫,放在这里做个[备份](https://blog.domineto.top/usr/uploads/2020/04/399029250.tar)吧。代码写的是真的烂……) ## Referrer http://172.104.107.6/python-tesseract-ocr/ 最后修改:2020 年 04 月 02 日 © 允许规范转载 赞 如果觉得我的文章对你有用,请随意赞赏