Loading... <div class="tip share">请注意,本文编写于 2551 天前,最后修改于 2548 天前,其中某些信息可能已经过时。</div> > 文章大部分来自一篇作者未知的文章,如有侵权请告知。 编码和密码是两种不同的东西。Wiki 上对编码的解释是: > 编码是信息从一种形式或格式转换为另一种形式的过程;解码则是编码的逆过程。 换句话说,编码是将原文转换为其他表达形式,为了解决一些问题。如传输不可见字符,统一格式等。下面总结一些常见的编码: ## 1. ASCII编码 想必学计算机的都对ASCII码很熟悉吧?ASCII编码大致可以分作三部分组成: - 第一部分是:ASCII非打印控制字符(参详ASCII码表中0-31); - 第二部分是:ASCII打印字符,也就是CTF中常用到的转换; - 第三部分是:扩展ASCII打印字符(第一第三部分详见 [ASCII码表](http://www.asciima.com/) 解释)。  ## 2. Base64/32/16编码 base64、base32、base16可以分别编码转化8位字节为6位、5位、4位。16,32,64分别表示用多少个字符来编码,这里以base64为例吧。Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据。包括MIME的email,email via MIME, 在XML中存储复杂数据。 ### 编码原理 Base64编码要求把3个8位字节转化为4个6位的字节,之后在6位的前面补两个0,形成8位一个字节的形式,6位2进制能表示的最大数是2的6次方是64,这也是为什么是64个字符(A-Z,a-z,0-9,+,/这64个编码字符,=号不属于编码字符,而是填充字符)的原因,这样就需要一张映射表,如下: 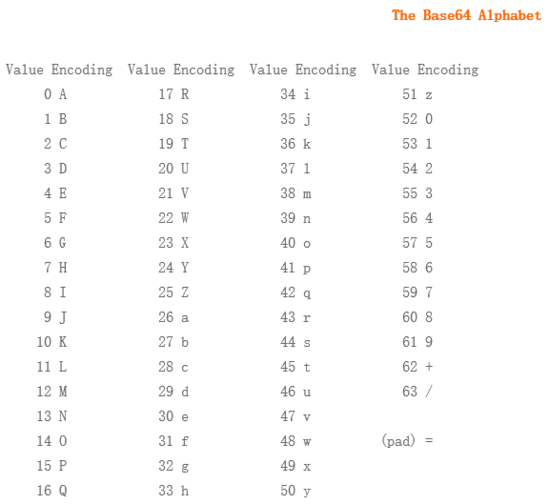 ### 举个例子(base64) 源文本:`T h e` 对应ascii码: `84 104 101` 8位binary:`01010100 01101000 01100101` 6位binary:`010101 000110 100001 100101` 高位补0:`000010101 00000110 00100001 00100101` 对应十进制数:`21 6 33 37` 查表:`V G h l` ## 3. shellcode编码 没用过…………参考这里吧:[传送门](https://www.xineting.club/2018/11/03/shellcode%E7%BC%96%E7%A0%81%E6%8A%80%E6%9C%AF/) ##4. Quoted-printable 编码 它是多用途互联网邮件扩展(MIME) 一种实现方式。有时候我们可以邮件头里面能够看到这样的编码,编码原理 [参考](http://blog.chacuo.net/494.html) 。 编码解码可以走这边: [传送门](http://www.mxcz.net/tools/QuotedPrintable.aspx) ## 5.XXencode编码 XXencode将输入文本以每三个字节为单位进行编码。如果最后剩下的资料少于三个字节,不够的部份用零补齐。这三个字节共有24个Bit,以6bit为单位分为4个组,每个组以十进制来表示所出现的数值只会落在0到63之间。以所对应值的位置字符代替。它所选择的可打印字符是:+-0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz,一共64个字符。跟base64打印字符相比,就是UUencode多一个“-” 字符,少一个”/” 字符。  源文本: `The quick brown fox jumps over the lazy dog` 编码后: `hJ4VZ653pOKBf647mPrRi64NjS0-eRKpkQm-jRaJm65FcNG-gMLdt64FjNkc+` 编码解码 [传送门](http://web.chacuo.net/charsetxxencode) ## 6.UUencode编码 UUencode是一种二进制到文字的编码,最早在unix 邮件系统中使用,全称:Unix-to-Unix encoding,UUencode将输入文本以每三个字节为单位进行编码,如果最后剩下的资料少于三个字节,不够的部份用零补齐。三个字节共有24个Bit,以6-bit为单位分为4个组,每个组以十进制来表示所出现的字节的数值。这个数值只会落在0到63之间。然后将每个数加上32,所产生的结果刚好落在ASCII字符集中可打印字符(32-空白…95-底线)的范围之中。 源文本: `The quick brown fox jumps over the lazy dog` 编码后: `M5&AE('%U:6-K(&)R;W=N(&9O>"!J=6UP<R!O=F5R('1H92!L87IY(&1O9PH*` 编码解码 [传送门](http://web.chacuo.net/charsetuuencode) ## 7.URL编码 url编码又叫百分号编码,是统一资源定位(URL)编码方式。URL地址(常说网址)规定了常用地数字,字母可以直接使用,另外一批作为特殊用户字符也可以直接用(/,:@等),剩下的其它所有字符必须通过%xx编码处理。 现在已经成为一种规范了,基本所有程序语言都有这种编码,如js:有encodeURI、encodeURIComponent,PHP有 urlencode、urldecode等。编码方法很简单,在该字节ascii码的的16进制字符前面加%. 如 空格字符,ascii码是32,对应16进制是'20',那么urlencode编码结果是:%20。 源文本: `The quick brown fox jumps over the lazy dog` 编码后: ``` #!shell %54%68%65%20%71%75%69%63%6b%20%62%72%6f%77%6e%20%66%6f%78%20%6a%75%6d%70%73%20%6f%76%65%72%20%74%68%65%20%6c%61%7a%79%20%64%6f%67 ``` 编码解码 [传送门](http://web.chacuo.net/charseturlencode) ## 8.Unicode编码 Unicode编码有以下四种编码方式: 源文本: `The` &#x [Hex]: `The` &# [Decimal]: `The` \U [Hex]: `\U0054\U0068\U0065` \U+ [Hex]: `\U+0054\U+0068\U+0065` 编码解码 [传送门](http://www.mxcz.net/tools/Unicode.aspx) ## 9.Escape/Unescape编码 Escape/Unescape加密解码/编码解码,又叫%u编码,采用UTF-16BE模式, Escape编码/加密,就是字符对应UTF-16 16进制表示方式前面加%u。Unescape解码/解密,就是去掉"%u"后,将16进制字符还原后,由utf-16转码到自己目标字符。如:字符“中”,UTF-16BE是:“6d93”,因此Escape是“%u6d93”。 源文本: `The` 编码后: `%u0054%u0068%u0065` ## 10.HTML实体编码  完整编码手册 [参考](http://www.w3school.com.cn/tags/html_ref_entities.html) ## 11.敲击码 敲击码(Tap code)是一种以非常简单的方式对文本信息进行编码的方法。因该编码对信息通过使用一系列的点击声音来编码而命名,敲击码是基于5×5方格波利比奥斯方阵来实现的,不同点是是用K字母被整合到C中。 敲击码表: ``` #!shell 1 2 3 4 5 1 A B C/K D E 2 F G H I J 3 L M N O P 4 Q R S T U 5 V W X Y Z ```  ## 12.莫尔斯电码 摩尔斯电码(Morse Code)是由美国人萨缪尔·摩尔斯在1836年发明的一种时通时断的且通过不同的排列顺序来表达不同英文字母、数字和标点符号的信号代码,摩尔斯电码主要由以下5种它的代码组成: 1. 点(.) 2. 划(-) 3. 每个字符间短的停顿(通常用空格表示停顿) 4. 每个词之间中等的停顿(通常用 `/` 划分) 5. 以及句子之间长的停顿 摩尔斯电码字母和数字对应表: ``` #!shell A .- N -. . .-.-.- + .-.-. 1 .---- B -... O --- , --..-- _ ..--.- 2 ..--- C -.-. P .--. : ---... $ ...-..- 3 ...-- D -.. Q --.- " .-..-. & .-... 4 ....- E . R .-. ' .----. / -..-. 5 ..... F ..-. S ... ! -.-.-- 6 -.... G --. T - ? ..--.. 7 --... H .... U ..- @ .--.-. 8 ---.. I .. V ...- - -....- 9 ----. J .--- W .-- ; -.-.-. 0 ----- K -.- X -..- ( -.--. L .-.. Y -.-- ) -.--.- M -- Z --.. = -...- ``` 源文本: `THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG` 编码后: ``` #!shell - .... . / --.- ..- .. -.-. -.- / -... .-. --- .-- -. / ..-. --- -..- / .--- ..- -- .--. ... / --- ...- . .-. / - .... . / .-.. .- --.. -.-- / -.. --- --. ``` 在线编码解码 [传送门](http://rumkin.com/tools/cipher/morse.php) 摩尔斯电码除了能对字母数字编码以外还对一些标点符号,非英语字符进行了编码,而且还有一些特定意义的组合称为特殊符号,比如 `·-·-·-·-·-` 表达的意思是调用信号,表示“我有消息发送”。如果感兴趣可以参考 [WiKi](https://zh.wikipedia.org/wiki/%E6%91%A9%E5%B0%94%E6%96%AF%E7%94%B5%E7%A0%81) 。 最后修改:2019 年 08 月 06 日 © 允许规范转载 赞 如果觉得我的文章对你有用,请随意赞赏