Loading... 首先我们生成一个大文件: ```bash # 生成一个 200M 的大文件 dd if=/dev/random of=test bs=1M count=200 ``` 将这个文件上传到 HDFS ```bash hdfs dfs -put test # push 到当前目录 ``` 进入存放 dataNode 的 block 目录: ```bash # 前面 /usr/local 是 Hadoop 的路径,中间 BP 后面的参数因人而异 cd /usr/local/hadoop/tmp/hdfs/data/current/BP-1815234426-127.0.1.1-1587059579940/current/finalized/ ls -lhrt # 查看 block 列表信息 ``` 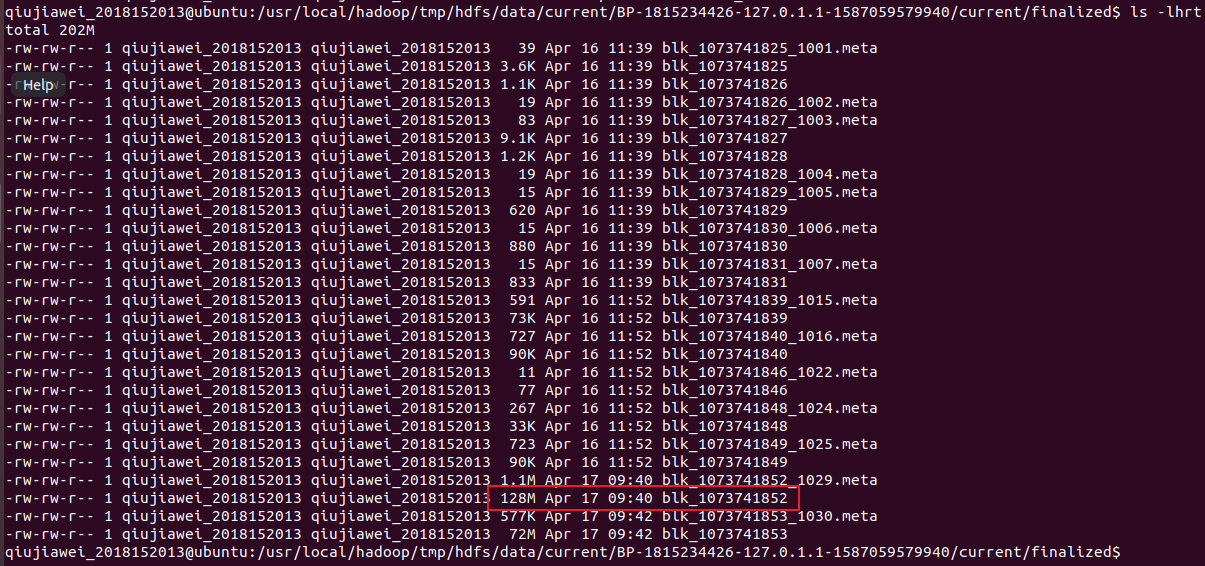 结论:hadoop dfs 根据默认值将文件拆分成最大为 128M(默认)大小 block 数据块 最后修改:2020 年 04 月 18 日 © 允许规范转载 赞 如果觉得我的文章对你有用,请随意赞赏